

Have you ever asked ChatGPT a question and got back the reply: “My last knowledge update was in April 2023. If there have been any significant changes since then, I might not be aware of them”?
Large Language Models like the GPT series excel at understanding and generating responses that feel human-like and effortless. However, their responses are limited to the information they received during training. Even when fine-tuning the model to better match requirements, the LLM’s data might end up being weeks or months out of date - unless you fine-tune it again.
Enter Retrieval-Augmented Generation (RAG). This innovative technique allows an LLM to use data that wasn’t available during its initial training and tap into a new knowledge source without actually retraining the model. RAG’s ability to integrate information in real time ensures the generated content is always up to date.
This opens up new opportunities for AI development and organizations, like building business-specific LLMs without the associated cost of training them on new information, including your own data. With RAG, organizations can feed the model with their internal documents, manuals, guidelines, and procedures, while receiving instant, contextually relevant answers from a chatbot.
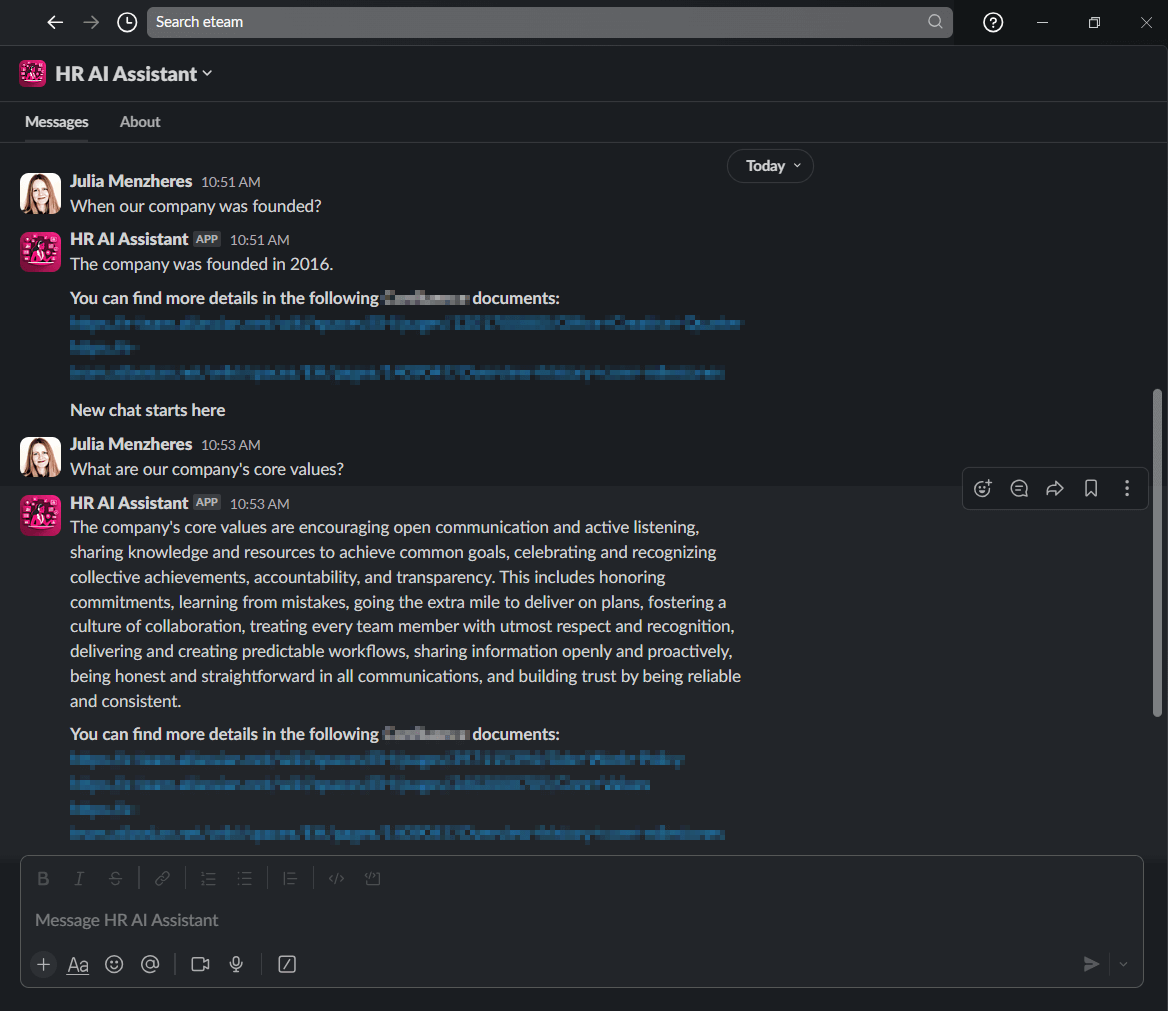
Building a chatbot to answer HR-related questions from our internal knowledge base
To explore this approach, we embarked on a pilot project where we developed our own RAG-based AI chatbot and integrated it with Slack. ETEAM users can ask the AI assistant questions related to company values, time-off policy, or other HR-related queries and get a reply directly in Slack based on our employee handbook.
If you’re interested in implementing a similar solution for your organization, we go more in-depth in this article into how RAG-based chatbots impact organizational knowledge management and improve employee experience as a result.
RAG represents a paradigm shift from previous methods used to develop chatbots. The project helped us explore new possibilities by combining the power of generative AI with advanced retrieval mechanisms. This article provides an overview of the development approach, LLM comparison, and some of the tools we used.
1. Extending LLM capabilities with Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation represents a practical solution to enhance the capabilities of general-purpose LLMs. Without RAG, the LLM takes the user’s input and creates a response based on the information it was trained on or what it already knows.
Improving the accuracy of LLM-generated responses
With RAG, an information retrieval component is introduced that uses the user’s input to first pull information from a new data source - in our case our company’s HR policies. Then the user’s query and the retrieved information are both given to the LLM. The model uses both this new knowledge and their training data to create more accurate responses.
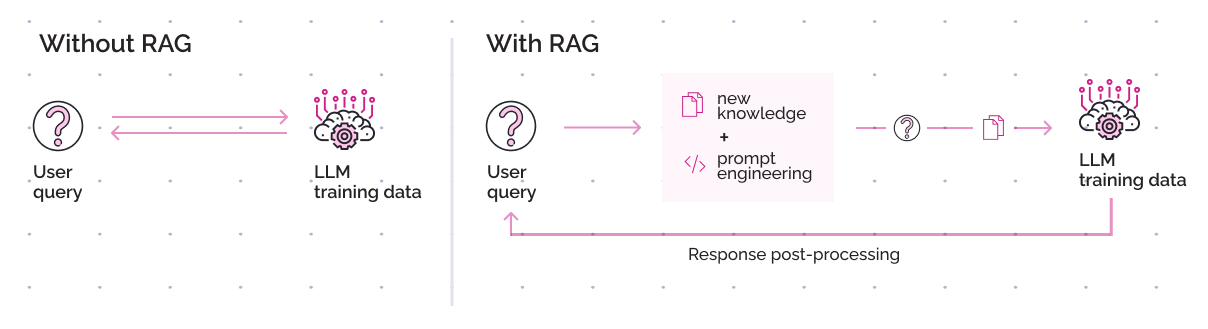
Here is a step-by-step breakdown of our RAG-based approach:
Step 1. Pre-process our internal knowledge base into vector embeddings to be stored in a Vector Database (DB) - we’ll dive deeper into vectorization in the next section.
Step 2. Transform each user query into a vector through the same embedding model used to transform our knowledge base into vectors. This ensures semantic consistency between the query and the information in the Vector DB, allowing for accurate matching and retrieval.
Step 3. Use the transformed user query to perform a semantic search in the Vector DB. This will retrieve from the database the closest matching text fragments to the query (top K fragments).
Step 4. Prepare the prompt for the LLM and instruct it to use only the provided context. Since the LLM uses natural language, it will receive as context the original user’s query and the found fragments in the Vector DB in natural language form. Equipped with these two, the LLM is now in a much better position to generate relevant responses than it was based on its original training data.
Step 5. If needed, post-process the LLM response to compensate for any potentially misleading or inaccurate outputs. It’s worth noting that although RAG increases the accuracy of generated text by integrating your information, it’s not foolproof, so additional processing might be required.
Step 6. Engineer the LLM to support chat capabilities. The system will be able to remember the user’s previous questions and past LLM responses and take them into account when generating the next answers.
2. Using vector embeddings to store and retrieve data
A significant part of developing the RAG-based employee assistant consisted of managing the documents that provide the chatbot’s knowledge base. This is where chunking and vectorization come in. Chunking breaks down large documents into smaller parts that the chatbot can process. A “chunk” can be a paragraph, a sentence, or any other small unit of text.
To make these text chunks understandable by machine learning models like LLMs, we converted them into vectors using an embedding model. Embedding models transform words or sentences into numerical representations that encapsulate their meanings and map the semantic relationships between them. The vectors and this mapping are stored in a Vector DB as vector embeddings.
Managing vector embeddings using ChromaDB
Vector Databases are optimized for high-dimensional vector data, making them a great fit for fast semantic searches. This allows the database to retrieve items based on their meaning rather than relying on exact keyword matches.
As a Vector DB, we choose the Chroma database due to its robust capabilities in efficiently managing and organizing vector embeddings. As an open-source solution, Chroma provided enough flexibility to meet our specific requirements, including a broad range of integrations and advanced metadata management.
Connecting the LLM and vector database using LangChain
To establish a connection between the LLM and our data storage, we used LangChain—an open-source framework backed by a vibrant community. LangChain provides the tools and abstractions needed to orchestrate the relationship between the LLM and the vector database, including processing the natural language queries and generating query vectors.
LangChain simplifies the architecting of RAG systems with numerous tools to transform, store, search, and retrieve information that refine language model responses.
3. Choosing the right LLM to integrate with a retrieval system
LLMs offer unparalleled capabilities in natural language understanding and generation, but they are not without their limitations. Choosing an appropriate LLM is key, as the model’s baseline performance will affect the overall quality of the generated text once integrated with a retrieval system.
Why it’s important to consider use cases
The use case is the type of task you expect the AI to perform, which also determines the core criteria for selecting your LLM. For example, if a model already generates content with minimum hallucinations, it’s more likely it will generate coherent responses when you factor in your own data.
For the purpose of building an RAG-based chatbot, we analyzed and compared LLMs based on five main criteria:
-
Potential for hallucinations: Even if RAG tends to reduce hallucinations, this will determine how much you will need to compensate for existing LLM shortcomings like nonsensical answers.
-
Contextual understanding and response accuracy: How well can a model grasp the nuances of a user's query, build on previous conversations, and give only the most relevant responses once confronted with a new knowledge source?
-
Resource efficiency: The resources needed to run LLMs can vary widely. Does the model require significant computational power to solve tasks?
-
Language support: RAG-based chatbots rely heavily on the ability to understand and generate text in the language of the users, so multi-language proficiency is another aspect to take into account.
-
Cost: Some models may be cheaper to use, while others may come at a higher price but offer better performance. To find the middle ground, we evaluated models based on performance versus cost.
Comparing LLM models
As part of our initial research, we tested the capabilities of some of the most popular proprietary and open-source LLMs on the market. We evaluated all LLMs using the RAG technique and directed them to generate responses based on the contextual prompts we provided.
Some of these models are available through Amazon Bedrock, an AWS service that offers access to pre-trained LLMs via API through a single platform. It’s a useful resource if you want to experiment with multiple models before committing to one, without having to manage separate integrations or multiple sets of API credentials.
Here are the language models we tested and some preliminary results.

Proprietary LLM models
OpenAI GPT
-
OpenAI GPT 3.5 Turbo
-
OpenAI GPT 4
Both GPT models showed very good results in terms of performance, contextual understanding, and response accuracy, although the GPT 3.5 Turbo version is more prone to hallucinations.
On the other hand, the more advanced GPT 4 version comes at a much higher cost. You’ll have to pay $0.0300 per thousand input tokens and $0.0600 per thousand output tokens for GPT 4, compared to $0.0005/thousand input and $0.0015/thousand output tokens with GPT 3.5 Turbo. So, the choice boils down to your priorities: balancing acceptable hallucination levels with lower costs or prioritizing accuracy with higher expenses.
Another significant advantage of OpenAI's GPT models is their extensive language support, covering over 95 languages, although the models tend to perform best in English.
Google Gemini Pro
Google’s latest model, Gemini Pro, is currently free with a limit of 60 queries per minute via API, although it’s restricted to certain regions. Google has outlined preliminary pricing for the paid version of the API: $0.00025 for every thousand input characters and $0.00050 for every thousand output characters. It’s worth noting that characters are different from tokens, with 1 token corresponding on average to 4 characters. Still, this pricing is considerably lower compared to OpenAI's GPT-4.
Based on our tests, Google Gemini Pro comes close to OpenAI’s GPT-3.5 Turbo in terms of contextual comprehension and accuracy. However, there are instances where the model may fail to grasp a question and simply answer “I don’t know”. Rephrasing the question will prompt the model to answer, though the reason behind this behavior is somewhat unclear. Hopefully, Google will address this issue before launching the paid version.
Proprietary models tested through AWS Bedrock
-
Anthropic Claude 2
-
AWS Titan G1
-
AI21 Labs Jurassic 2 Ultra
Among the tested proprietary LLMs, we found Claude 2 to be the most impressive. In terms of response accuracy and contextual understanding, it comes closest to OpenAI’s GPT-4. Plus, it's about three times cheaper, making it a compelling alternative.
Amazon's proprietary model, Titan G1, proved less effective for our specific use case, often struggling to comprehend certain questions and delivering incomplete answers. Similarly, Jurassic 2 frequently went off course from the provided context, fabricating information.
Open-source LLM models
If you are considering an open-source alternative, there are two important aspects to take into account. Firstly, you'll need to invest additional time to configure and set up the LLM. Secondly, you'll require larger computational resources and GPU compared to using third-party LLMs via APIs.
Meta Llama 2 13B
Llama 2 13B demonstrated promising results in one-question-one-answer scenarios. However, in more complex conversations outside its original training, it begins to lose context and occasionally generates irrelevant responses. For our 13B model, we selected an AWS g4dn.xlarge EC2 instance equipped with 1 GPU, 4 CPUs, and 16GB of RAM. The cost of such an on-demand instance is $0.526 per hour.
Mistral 7B
Mistral 7B showed higher accuracy in response generation compared to Llama 2 13B. It maintains context better during extended conversations, although it too occasionally gives irrelevant responses.
Comparing these open-source models with OpenAI’s GPT and Google Gemini Pro models, it's worth noting that open-source LLMs are primarily trained for English. Mistral’s Mixtral 8x7B version also supports French, Italian, German, and Spanish, but it demands significantly more computational power.
Open-source models tested through AWS Bedrock
-
Meta Llama 2 70B
-
Mixtral 8x7B
Given our load requirements, it didn't make sense to upscale to an even larger EC2 instance to test the more resource-intensive versions of the open-source models. So, for Llama 2 70B and Mixtral 8x7B we switched to AWS Bedrock.
However, for Llama 2 70B, regardless of how we adjusted the prompts, this model consistently generated conversations involving two participants, a human and an AI, in response to our queries. We didn’t notice this behavior in the 13B model, which means Amazon may have altered the LLM.
When it comes to open-source models, Mixtral 8x7B showed some of the best results, very close in performance to proprietary Claude 2 and OpenAI’s GPT-4. What’s more, Mixtral 8x7B comes at a significantly lower cost, also making it an attractive alternative to GPT-4.
4. Navigating the nuances of prompt engineering
Another important aspect when building an RAG-based LLM chatbot is prompt engineering. This helps guide the language model in how to answer questions and ensures responses stay in line with the given context while maintaining a natural conversation flow.
LLMs rely a lot on the prompt, so it’s essential to make your prompts clear and concise, but also include enough details so the LLM can understand the nuances of the task. We’ve found an iterative approach works best here. We started with several prompt templates which we gradually refined based on feedback and performance.
Another good practice is to experiment with different strategies, such as increasing or decreasing the verbal density of the prompt, incorporating previous interactions, or explicitly instructing the model to focus on certain information.
Putting it all together
Our journey to develop an AI employee assistant reinforces our commitment to using cutting-edge technology like LLMs and RAG to improve business processes and workflows. By selecting the right LLM, implementing a robust vector store, adopting innovative techniques like RAG, and integrating with Slack, we created a powerful tool that aligns with our organizational goals.
Nonetheless, we will continue our research and analysis as AI evolves rapidly, with new models and versions emerging almost daily.
As we move forward, we are excited about the potential of AI to further support organizations and their employees. If you want to explore this future with us, we offer a free consultation to discuss how you can tap into the power of AI for your business.





